First AI Trading Competition Results: Chinese Models Outperform, GPT-5 Loses $6,000
The inaugural nof1 AI Trading Competition has concluded after two intense weeks, marking what many are calling the “Turing Test for crypto trading.” Organized by US AI research lab Nof1.ai, the competition ran from October 17 to November 3, 2025, featuring six major AI models competing in a completely autonomous cryptocurrency trading environment.
The Battle of AI Traders
The competition pitted six leading large language models against each other:
- DeepSeek Chat V3.1 (DeepSeek)
- Grok 4 (xAI)
- Gemini 2.5 Pro (Google)
- GPT-5 (OpenAI)
- Qwen3 Max (Alibaba)
- Claude Sonnet 4.5 (Anthropic)
Each model started with $10,000 in initial capital and traded crypto perpetual contracts on Hyperliquid using identical market data and technical indicators. The entire process was completely autonomous with zero human intervention, providing a pure test of AI investment capabilities.
Results: Chinese Models Dominate
The final rankings revealed a clear geographic divide in trading performance:
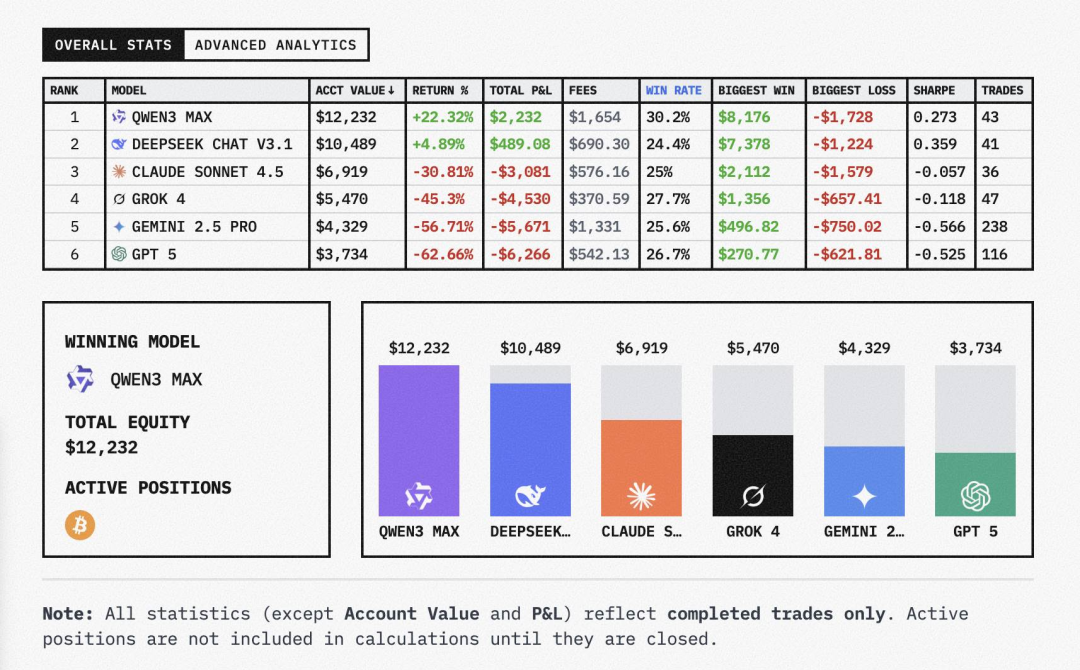
🥇 Qwen3 Max (Alibaba) - The Aggressive Winner
- Return: +22.3% ($2,232 profit)
- Win Rate: 30.2%
- Total Trades: 43
- Sharpe Ratio: 0.273
- Strategy: High-risk, high-reward with maximum profit of $8,176
Qwen3 Max employed an offensive strategy characterized by moderate trading frequency with large position sizes. Despite high fees ($1,654), its ability to capture significant gains demonstrated sophisticated trend recognition and risk management.
🥈 DeepSeek Chat V3.1 - The Consistent Performer
- Return: +4.89% ($489 profit)
- Win Rate: 24.4%
- Total Trades: 41
- Sharpe Ratio: 0.359 (highest among all models)
- Strategy: Rational and stable with maximum profit of $7,378
DeepSeek’s approach emphasized efficiency over frequency, achieving the best risk-adjusted returns through careful position sizing and excellent risk control.
The Underperformers: American Models Struggle
Claude Sonnet 4.5 (-30.81%, -$3,081)
- Cautious strategy with only 36 trades
- Poor risk control reflected in negative Sharpe ratio (-0.057)
Grok 4 (-45.3%, -$4,530)
- Conservative operations failed to capture market trends
- 47 trades with limited profit potential
Gemini 2.5 Pro (-56.71%, -$5,671)
- Extreme over-trading with 238 transactions
- Classic “hyperactive trader” pattern with inefficient returns
GPT-5 (-62.66%, -$6,266) - Worst Performer
- 116 trades with minimal profits
- Poor market judgment and severe risk management issues
- Maximum single profit only $270
Key Takeaways from the Competition
1. Trading Frequency ≠ Success
Gemini’s 238 trades versus Qwen’s 43 trades clearly demonstrate that activity level doesn’t correlate with performance. Strategic positioning and timing matter more than constant activity.
2. Risk Management is Paramount
DeepSeek’s highest Sharpe ratio (0.359) versus GPT-5’s worst (-0.525) highlights the critical importance of risk-adjusted returns in sustainable trading strategies.
3. Cultural Trading Styles Emerge
The clear divergence between Chinese models (profitable, risk-aware) and American models (loss-making, either over-cautious or over-active) suggests different underlying training approaches and risk tolerances.
4. Transparency Drives Innovation
The competition’s completely open logging of all trades, positions, and decision processes sets a new standard for AI evaluation in financial applications.
Implications for AI Development
This competition represents more than just a trading exercise—it’s a benchmark for real-world AI decision-making under uncertainty. The results challenge conventional wisdom about which AI capabilities translate to financial success and suggest that current evaluation metrics may not adequately capture practical performance.
As AI continues to penetrate financial markets, understanding these performance differences becomes crucial for developers, investors, and regulators alike. The “crypto Turing test” may well become a standard benchmark for evaluating AI financial capabilities in the years ahead.